階層型データベース
階層型データベースは、エッジが主役となってクラウドとの協調を最適化するIoT時代のDBMSソリューションです。
IoTデータの総合活用プラットフォーム
センサーデータの全てをクラウドに集めることが現実的でなくなってきています。この状況において、階層型データベースによるプラットフォームは、急増し続けるセンサーデータを個々のIoTデバイスに蓄積して一元管理し、全デバイスデータの総合的な検索を可能とします。
大量のIoTデバイスが接続する大規模なシステムにおいて、デバイス側(エッジ)で検索した結果を集めて利用。IoTデータの活用においてこれまでにない新しい仕組みをご提供します。
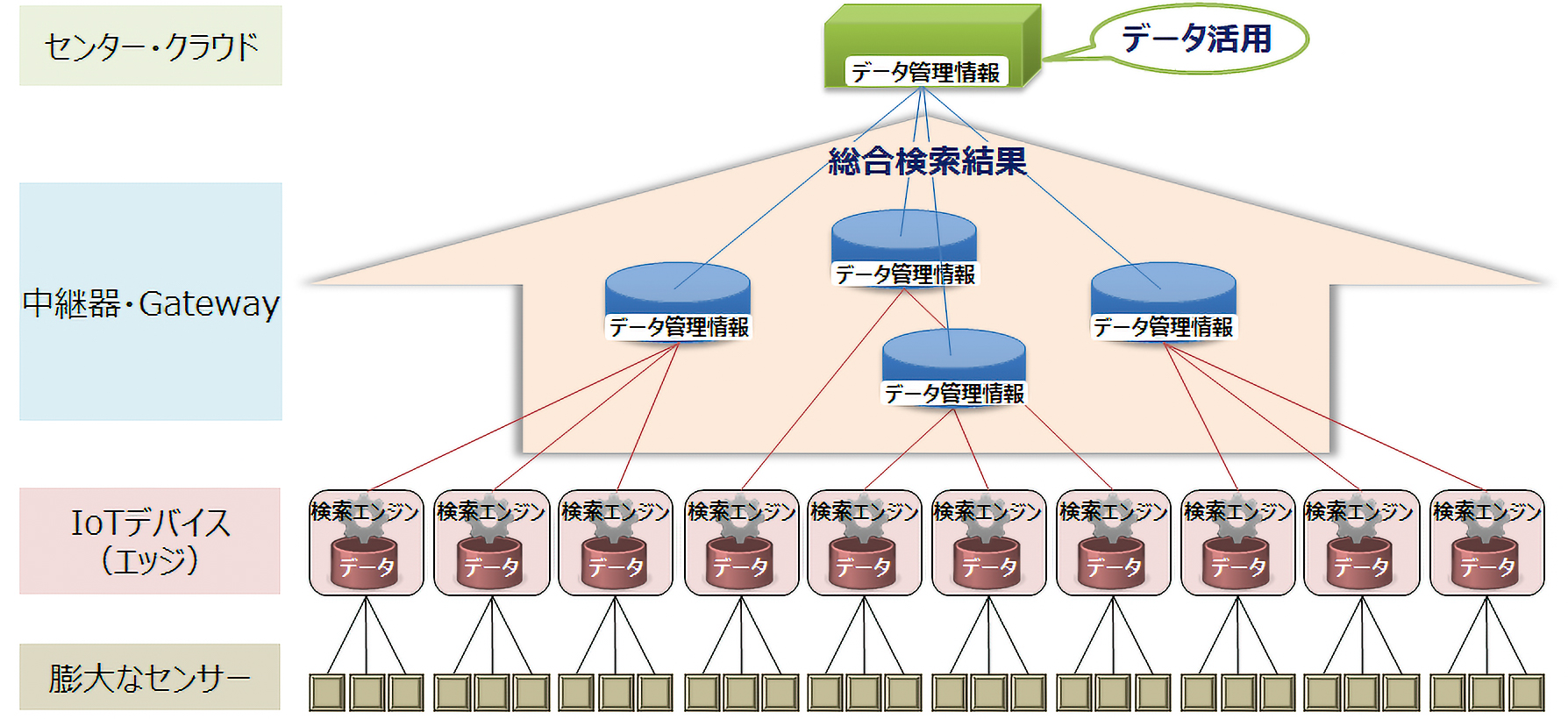
階層型データベースの構造
末端層・中間層・最上位層の各DBによって全体で1つの仮想的なDB(階層型DB)を形成し、利用者はそこから必要なデータを取得します。データの実体は末端層のDBのみが持ち、主要なデータ処理も末端層で行う。エッジのリソースを有効活用して、クラウドに依存しない効率的な総合検索を実現します。

当社は、2019年7月に本ソリューションの事業化のため、JV(DendritikDesign株式会社)に共同出資しました。階層型データベースの詳細はDendritik Design株式会社の公式ウェブサイト(https://dendritik.design/)をご参照ください。
トライアル版の提供について
当社では、階層型データベースの活用に関するPoC/プロトタイプをご支援するに向けて、階層型データベースのトライアル版をご提供しています。
トライアル版は製品版に対して機能的な相違はありませんが、以下の制限があります。
- 使用できる期間に限りがあります
- PoC/プロトタイプへの使用に限定されます
(システムの本開発/実運用への使用はできません)
階層型データベーストライアル版・ご提供価格: 20万円(税抜)
また、当社ではトライアル版のご提供と併せてPoC/プロトタイプに向けたコンサルティング・技術支援を行っています。
詳細については下記の「お問い合わせ」ページから問い合わせください。