高速ツリーアルゴリズム “STree”
高速屋が保有する独自技術の大本は、グラフ理論における「木構造」をベースとしたアルゴリズムとデータ構造”STree(エス・ツリー)”です。構造がコンパクト(省メモリ)でかつ、データの格納も、格納後の検索も極めて高速なデータ格納技術です。CPUの使用効率が良く、圧倒的な省電力を実現します。
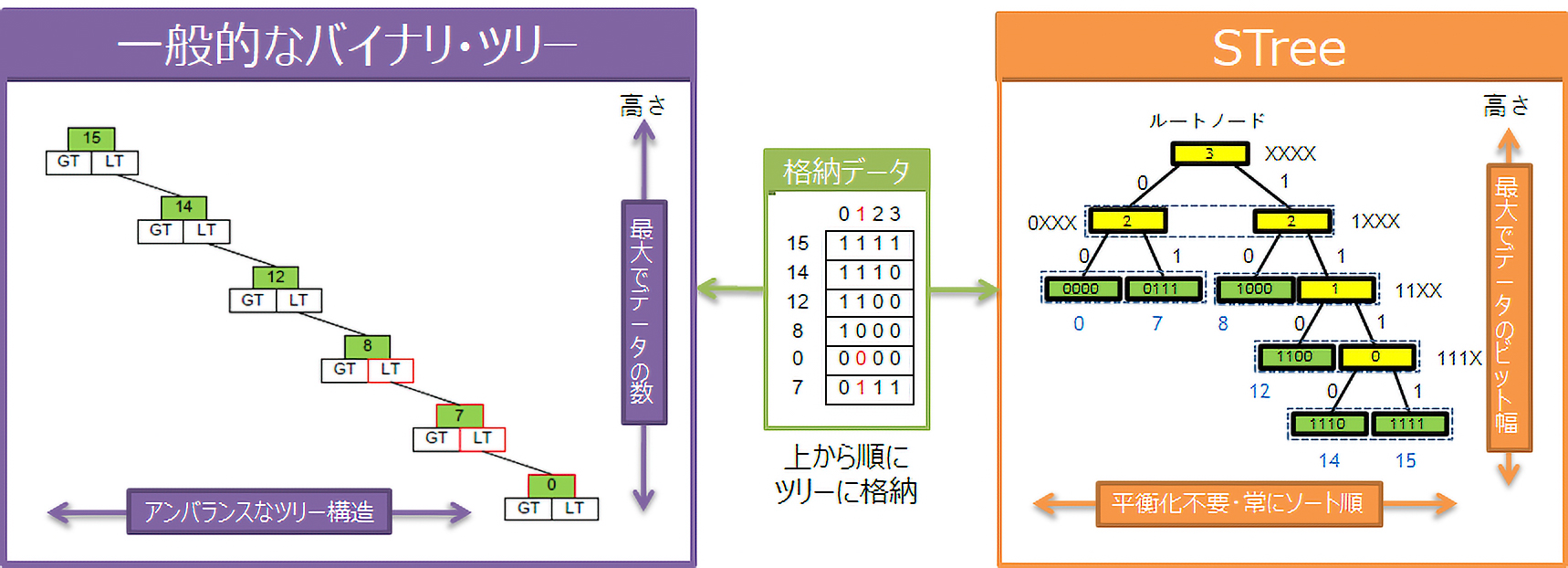
高速ツリーアルゴリズム “STree”の特徴
〈データ構造〉コンパクト(ブランチノードにデータを保持しない)
〈参照〉ツリーを辿る途中に分岐命令がない高速トラバース(パイプラインを乱さない)
〈格納〉高速(更新ノードが一ヶ所で済む)
〈ツリーのリーフの並び〉ソート順(昇順・降順の範囲取出し、近傍検索なども高速)
〈ツリーの高さ〉最大でデータのビット幅(ツリーの平衡化が不要)
適用先の例
組み込みデータベース向け高速検索・ソートエンジン
デバイスの限られたリソースを高効率に利用する高速データベースの実現
階層型DBにおけるエッジ内データベースでの高速検索技術に適用
組み込み型・ストリーム・プロセッシングエンジン
時々刻々と発生するストリームデータに対する高速かつ高度な統計処理の実現
大規模データ向け高性能ソート・マージエンジン
中間ファイル作成による分割・並列処理によって少量メモリで高速なソート・マージを実行
独自データ処理エンジンにおけるデータ加工コマンド群の内部処理に適用
学習圧縮
今後急増していくIoTデータへの対応として、通信の高効率化の実現が不可欠です。学習圧縮は、時々刻々と発生するセンサーデータなどの固定長bit列を低負荷・省メモリで高速に高圧縮・伸張する技術です。変化が乏しいカラムデータのエントロピーに着目し、高圧縮を僅かなCPUリソースで実現。膨大なIoTデータの通信量を大幅に削減できます。

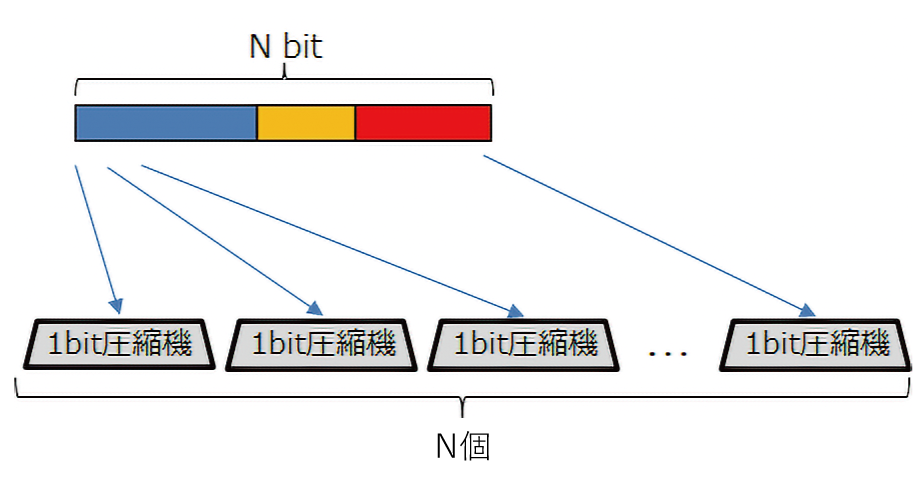
学習圧縮の概念
Nbitの固定長データに対して1bitの圧縮機をN個用意
周期的に観測されるセンサーデータは大きく変化することが少なく、データを「横」に見て圧縮するのではなく、「縦」に見たときの特徴を利用して圧縮効率を高める
学習圧縮の特徴
〈即時性〉1レコード毎に送受信が可能。端末側でデータを蓄積する必要が無い
〈省メモリ〉メモリ使用量が従来方式(zip圧縮等)よりも圧倒的に少ない
〈低負荷(CPU)〉データを蓄積して処理しないため、CPUを大きく占有する時間が生じない
〈高圧縮〉得意な時系列データにおいてはzip圧縮よりも高い圧縮率を実現
〈実装が容易〉送受信側で事前に共有すべき情報はデータサイズ(固定長のbit数)のみ
送受信側共に、薄いソフトウェアレイヤーを一枚噛ませれば実装可能
適用先の例
IoTにおけるエッジ~クラウド間データ通信
階層型DBにおけるエッジ層のレコードデータを上位に上げる際の圧縮ロジックに適用